Introduction
Structuring Information in Ontologies.
Ontologies provide a natural structure for information.
Ontologies provide an intuitive way of structuring information into domains of interest. IT Ontologies are extremely useful for structuring and associating information and have become popular and applicable since their introduction into IT, probably first in Artificial Intelligence in the early 1980s. They have become increasingly popular as there are many obvious benefits of the intuitive structure and organization and in that regard supersede the traditional class structures. Ontologies are ideally suited for organizing information with shared characteristics and structurally are part of our logical heritage and thus instinctively natural and easy to work with.
1
An Ontology is a hierarchical structure of meta-information.
An Ontology is a repository of meta-information—completely independent from any proprietary system, and thereby open and fully accessible by all.
Developing Ontologies
Analysis and Documentation
There are several basic steps in analyzing and documenting information. The following procedure is general, but applicable in many cases. It follows the general scheme recognized by international management planning: moving from analysis through planning. The process presented here only shows the upper levels of the common 7 level model as an Ontology is a tool that applies at these levels. In particular, is beneficial as an additional documentation tool or even as a replacement for some of the first levels of a traditional approach:
3
An Analysis Procedure using
The most difficult concept to grasp in creating Ontologies is to realize the abstraction between referencing objects and modelling situations that contain objects.
as we are mostly exposed to flow-chart like structures activity diagrams, control-flow charts, etc. Ontologies document a higher level of abstraction, and preclude interactions.)
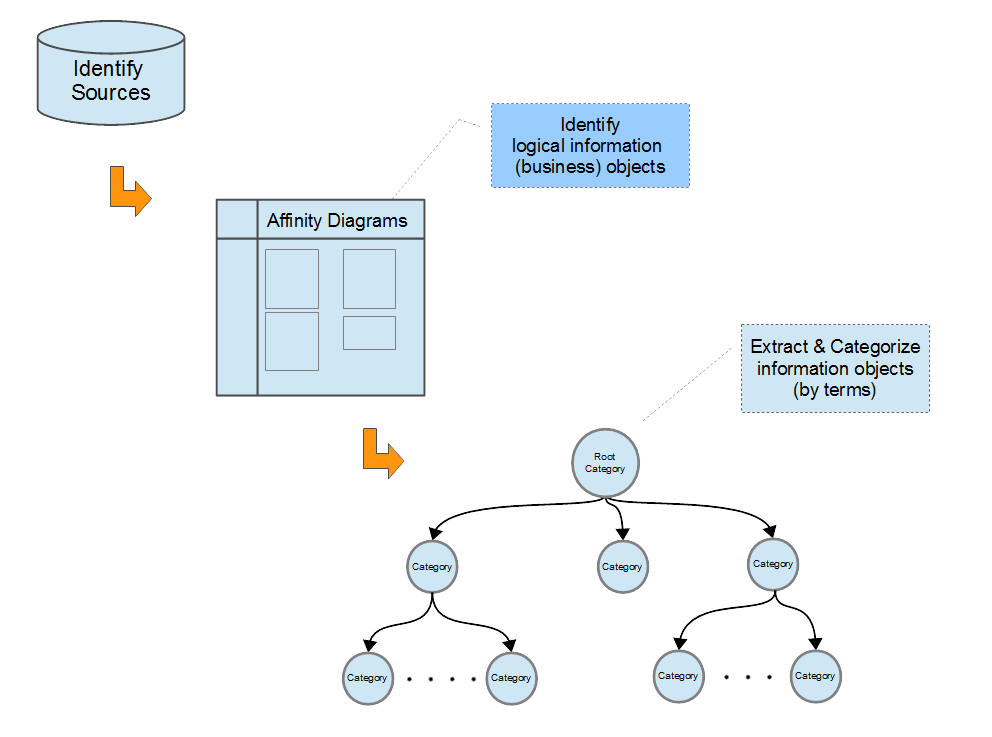
0. Identify Sources
The domain being analyzed will have a some quite obvious sources: databases, data warehouses, etc. but quite likely also a number of important but somewhat diffuse sources such as: un-structured information such as documents, emails, presentations, etc. which may or may not be included in the analysis process. This is particular to each application.
1. Grouping Logical Information
In a traditional planning process, Affinity Diagrams are commonly used to advantage when sorting out the logical information groups and is recommended as a first step (logical grouping of information) in the analysis. Another advantage of Affinity Diagrams is that they can be used to group information in un-structured documents. Affinity Diagrams are commonly built from a bottom-up perspective and thereby provide a way of organizing information into hierarchies. This is particularly useful where there is no obvious overall structure, e.g., in letters, eMails, and other un-structured documents. Working with Affinity Diagrams typically breaks information into groups and logical constructs. This is a useful step and can provide insight into the right grouping of information objects into the relevant ontology hierarchies.
2. Populating the Ontology
Creating the upper levels of an ontology can be quite time consuming. Fortunately, there exist several pubically available upper-level ontologies. On the other hand, most of these are too detailed for the pragmatics of organizing data sources. provides some simple and ubiquious higher-level Categories for starting Ontologies (see below).
Building upon the upper level structures, Categories can be created from the logical groups delineated in the Affinity Diagrams. Often intermediary Categories will become obvious, creating natural orders of information and eventually culinataing the in the Categories that are recognizable as information objects in the domain.
The Affinity Diagrams are also a major source of the intrinsic Characteristics that are needed to specify the uniqueness of a Category. As well, many extrinsic Characteristics will be available from the information in the diagrams.
Adding Relations
To further complete the documentation of the Categories, one can appeal to another of the traditional tools: Relations Diagrams. This can often be confusing when creating an Ontology as the Relation Diagrams are mostly concerned with interactions between information and not pure relational aspects.
Other diagrams in the Management and Planning process can be mined to add details to the Ontology. Tree Diagrams and Matrix Diagrams can also provide details that ought to be documented in the Onotology.
The traditional Management and Planning process can be found in many sites and one of the best is: ASQ.ORG − ref. Nancy R. Tague’s The Quality Toolbox, Second Edition, ASQ Quality Press, 2004.
in Analyis and Planning
In the process, the first step is to include the sources that are to be addressed in this domain. has the additional function of documenting sources and this is information will be added to the ontology. The process steps
Start with the Core Set
In methodology, an Ontology is developed starting from the high level; usually the highest level of Categories (information objects) considered practical for the organization. To facilitate creating new Ontologies, the Reference Ontology has been developed. The Reference Ontology is an upper-level Ontology with a number of generally applicable, ubiquitous Categories that can be imported to supplement or to start into new Ontologies. Importing Categories from the Reference Ontology is a quick way of establishing a foundation level of Categories in a new application Ontology. After the Categories are imported into an application Ontology they can be progressively customized to fit the organizations application information. The diagram, Fig. 1 (below) is an example of some of the higher-level Categories that can be imported into a new Ontology.
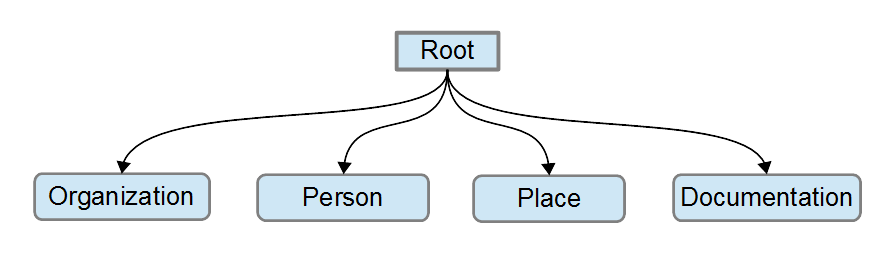
3
A simple set of upper-level Categories.
The simple − yet relevant Categories in the Reference Ontology provide good initial levels for most application Ontologies. All Categories inherit characteristics from the ROOT, the basis system Category, and all Categories will therefore have intrinsic characteristics such as: identity, description (text) and some extrinsic (optional) attributes, such as creation-date, author, etc.
Expanding the Ontology − Dividing into sub-Categories
The tenets on expanding or sub-dividing an application Ontology,i.e., creating new Categories are:
The Ontology is a hierarchical (tree) structure
In an Ontology is a simple hierarchical tree—not a directed graph.
Categories inherit from their immediate parent.
Creating a new layer of Categories (sub-dividing the parent) produces sub-categories with all of the characteristics and attributes of the parent − simple hierarchical inheritance.
Each and every Category is unique
All categories are unique and when sub-dividing; child Categories must be orthogonal to one another (non-overlapping). In practice this means that there must be at least one unique intrinsic characteristic in each Category. There is no restriction that Categories need to be components of the parent—only aggregates.
The domain of a Category is determined by its intrinsic Characteristics
The intrinsic characteristics of a Category determine its conceptual place in the Ontology and make it unique among Categories.
Expanding the Core Set (example)
From the Core Set above (Fig. 1) Categories can be sub-divided: For example: The ORGANIZATION Category could be further partitioned into relevant Categories (particular to the information resources being analyzed), e.g., companies, educational , non-profit, etc. Intrinsic characteristics would then be added to each of these to create unique Categories, but still within the domain of the parent. Similarly, DOCUMENTATION could be further partitioned into the types of documents that the information analysis reveals, e.g., office documents, exams, letters, emails, etc. And as well, PLACE would most definitely be subdivided (example below). However, PERSON would not likely be subdivided and this is discussed under the section Granularity, below.
Expanding the example (from above)
ORGANIZATION
ORGANIZATION is a general Category that can be imported from the Reference Ontology. The addition of intrinsic characteristics could further refine ORGANIZATION to suit the application Ontology being developed. Then, ORGANIZATION can be divided into sub-categories, each being more specific and targeting the application information.
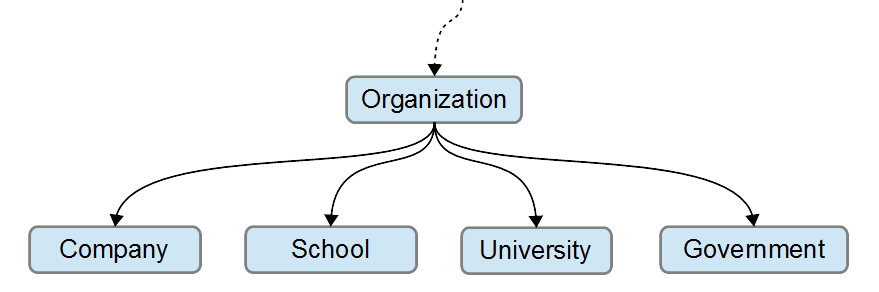
2
An example of how the Category ORGANIZATION could be divided into sub-categories.
PERSON
PERSON is a ubiquitous category and is found in the reference ontology. If we were to give it a parent it would probably be “Animal”, but in this Ontology we are only interested in people—not other branches such as dogs and horses.
Some intrinsic characteristics of this category would probably include: birth-date, mother, father, parents, birthplace. Extrinsic characteristics would most likely include: identification (such as names, ids, national registration numbers, etc.)
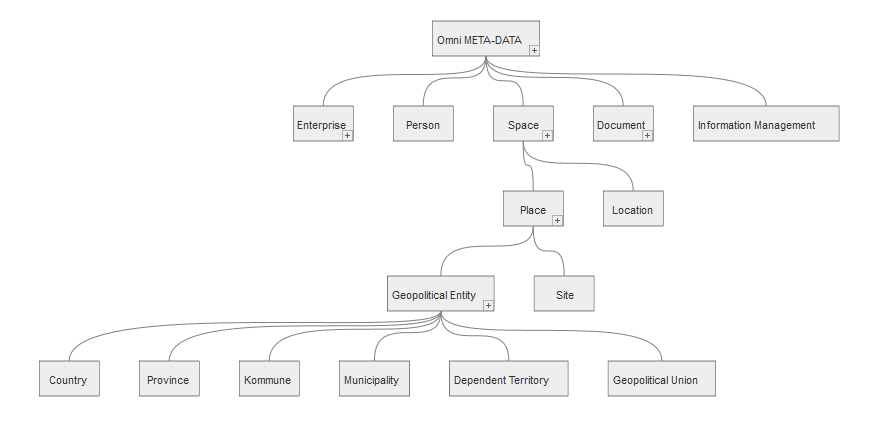
PLACE
A PLACE is a high-level Category, useful in many applications for delineating sub-categories that may contain geopolitical entities or just places of interest such as buildings, institutions, etc.

3
The Category PLACE sub-divided into GEOPOLITICAL ENTITIES and SITE sub-categories.
DOCUMENTATION
DOCUMENTATION is general category from the Reference Ontology and could be further partitioned into the types of documents that the information analysis reveals, e.g., office documents, exams, letters, emails, etc. Or, as here, simple ELECTRONIC and PAPER Categories.

4
DOCUMENTATION can be categorized in many ways, for example a simple division into PAPER and ELECTRONIC sub-categories.